DrQA基于维基百科数据的开放域问答机器人实战教程
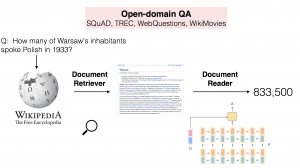
DrQA 是一个基于维基百科数据的开放域问答系统,它由检索器和阅读器组成。其中检索器用于从海量的文本(例如维基百科)中获得相关的文章;阅读器用于从文章中获得相应的答案。
官方介绍:
DrQA是一个应用于开放域问答的阅读理解系统。特别是,DrQA的目标是“大规模机读”(MRS)。在这个设定中,我们在可能非常大的非结构化文档集中搜索问题的答案。因此,系统必须将文档检索(查找相关文档)的挑战与机器对文本的理解(从这些文档中识别答案)的挑战相结合。
我们使用DrQA的实验侧重于回答factoid问题,同时使用Wikipedia作为文档的独特知识源。维基百科是一个非常适合大规模,丰富,详细信息的来源。为了回答任何问题,必须首先在超过500万个文章中检索可能相关的文章,然后仔细扫描它们以确定答案。
请注意,DrQA将Wikipedia视为一个通用的文章集合,并不依赖于其内部知识结构。因此,DrQA可以直接应用于任何文档集合。
数据集:维基百科
框架:PyTorch
版本:PyTorch torch-0.3.0
论文:Reading Wikipedia to Answer Open-Domain Questions
项目:https://github.com/facebookresearch/DrQA
系统架构:
实战:
交互模式下提问:
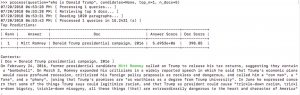
where is stanford university
可以看到检索到的文档是 Stanford University,问题的答案是:浅绿色标注的部分,答案非常的精准。

交互模式下提问:
where is Barack Hussein Obama from
交互模式下提问:
回答不是很精准,我其实想问的是奥巴马来自哪里。答案返回的是奥巴马在哪里,奥巴马在华盛顿,不过也还是相当不错。

who is Donald Trump
这个问题并没有找到准确的答案,虽然文档是相关的。
原创文章,作者:pytorch,如若转载,请注明出处:https://pytorchchina.com/2018/07/20/drqa/
相关推荐
-
PyTorch Linux 安装教程
打开 pytorch.org 官网,可以选择安装器,Python版本,CUDA 版本。 例如 Linux Pip Python3.6 CUDA 9.0 的安装命令为: pip3 i…
-
PyTorch 60 分钟入门教程:PyTorch 深度学习官方入门中文教程
什么是 PyTorch? PyTorch 是一个基于 Python 的科学计算包,主要定位两类人群: NumPy 的替代品,可以利用 GPU 的性能进行计算。 深度学习研究平台拥有…
-
PyTorch 60 分钟入门教程:数据并行处理
可选择:数据并行处理(文末有完整代码下载) 作者:Sung Kim 和 Jenny Kang 在这个教程中,我们将学习如何用 DataParallel 来使用多 GPU。 通过 P…
-
PyTorch 官方中文教程包含 60 分钟快速入门教程,强化教程,计算机视觉,自然语言处理,生成对抗网络,强化学习!
官方教程包含了 PyTorch 介绍,安装教程; 60 分钟快速入门教程,可以迅速从小白阶段完成一个分类器模型;计算机视觉常用模型,方便基于自己的数据进行调整,不再需要从头开始写;…
-
PyTorch Windows 安装教程
pytorch 正式发布支持 Windows 的 0.4 版 安装教程: 从官方网站选择对应的版本和安装工具,这里我选择了 Windows + pip 命令是: pip3 inst…
-
PyTorch Mac 安装教程
打开 pytorch.org 官网,可以选择安装器,Python版本,CUDA 版本。 例如 Mac Conda Python3.6 CUDA 9.0 的安装命令为: conda …
-
PyTorch Lightning 专门为机器学习研究者开发的PyTorch轻量包装器
PyTorch Lightning 专门为机器学习研究者开发的PyTorch轻量包装器(wrapper)。缩放您的模型。写更少的模板代码。 持续集成 系统/ PyTorch版本 1…
-
PyTorch Windows 安装教程:两行代码搞定 PyTorch 安装
打开 pytorch.org 官网,可以选择安装器,Python版本,CUDA 版本。 例如 Windows Pip Python3.6 CUDA 9.0 的安装命令为: pip3…
-
transformers 预训练模型
作者|huggingface 编译|VK 来源|Github 这里的预训练模型是当前提供的预训练模型的完整列表,以及每个模型的简短介绍。 有关包含社区上传模型的列表,请参阅http…
-
Transformers 快速入门
transformers 作者|huggingface 编译|VK 来源|Github 理念 Transformers是一个为NLP的研究人员寻求使用/研究/扩展大型Transfo…